올해 CVPR 2022 에서 발표된(arxiv 등을 통해 진작에 공개된) paperwithcode 기준으로 현재까지 state-of-the-art의 성능을 지닌 방법이라 읽어 봤다(더 자주 보고 정리해야하는데 큰일이다).
Motivation
Anomaly detection 연구에 있어서 가장 어려운 점은 대부분의 abnormal data가 매우 드물다는 점이다. 그렇기 때문에, anomaly detection 관련 연구는 기본적으로 normal data의 본질적인 분포나 특징을 학습하는 것에 있습니다. 이를 위하여 autoencoder나 gan을 활용하여 네트워크 타겟 데이터에 대한 특징을 학습하도록 하는 연구도 많이 이루어졌었는데, 최근에는 이러한 과정 없이 ImageNet에 대해 pre-trained 네트워크에서 생성된 normal data 들의 feature의 분포를 바탕으로 학습하지 않은 abnormal(outlier)를 검출하는 방향으로 많은 연구가 진행되는 듯하다. 이런 접근 방식의 특징은 추가적인 학습을 필수로 진행하지 않는다는 점입니다. 하지만, 미리 pre-trained 된 네트워크는 학습된 데이터에 대해 어느정도 bias가 있을 수 밖에 없다. 이 논문에서는 그러한 문제점들을 해결하고 성능을 높이기 위한 방법을 제안한다.
normal한 data에 대한 feature를 추출하여 memory bank에 저장하는 과정은 필요하다. memory bank에 저장하는 건 anomaly detection 에선 이젠 매우 흔한 접근방법 인거 같다. 처음엔 feature space 자체를 제한하는 방식이 더 fancy하다고 생각했는데, 지금 생각해보면 memory bank를 활용하는게 성능측면에선 더 유리 한 듯 느껴진다.
Methodology(PatchCore)
PatchCore는 ImageNet에 대해 pre-trained된 backbone 네트워크를 활용한다(PaDiM, SPADE 등 비슷한 방법론 동일).방대한 데이터(ImageNet)에 대해서 학습된 네트워크는 비록 약간의 bias가 있을지라도(결국은 ImageNet 데이터의 class를 분류하는 것을 목적으로 학습되었기 때문에) 일반적인 이미지의 feature을 추출하기에 적합하다.딥러닝 기반의 특징을 활용하는 대다수의 방법들은 네트워크의 최종단에서 얻어진 특징을 활용한다. anomaly detection은 입력 이미지가 어떤 물체인지 분류하는 것이 목적은 아니지만 기 학습된(pre-trained) 네트워크를 통해 추출된 특징을 기준삼아 정상/비정상을 비교하는 것도 가능은 합니다.이 경우 이미지가 어떠한 특성을 가지는 지 분류하기 좋지만 지역적인 정보 측면에서는 손실이 있을 수 밖에 없다. 하지만, 주로 anomaly detection에서 관심있어 하는 부분은 주로 이미지의 굉장히 작은 부분에서 나타난다. 따라서, PatchCore에서는 Locally aware patch feature을 제안한다. 즉, 전체 네트워크의 마지막 단에서 추출된 특징을 활용하는 것이 아니라 중간에서 추출된 특징을 활용한다(Resnet50 기준 2,3 stage 마지막 단 feature). 네트워크의 중간에서 추출된 특징은 이미지의 일부분에 대한 특징이기 때문에 국소적인 차이를 구별하는데도 유용하다는게 저자의 주장이다. 하지만, 너무 작은 이미지 단위에 집중하면 정상 데이터안에서도 존재하는 작은 지역적 변화에 민감하게 반응 할 수 있기 때문에 PatchCore에서는 주변 특징들을 포함한 특징을 생성한다. 말로는 뭐 복잡해보이기는 한데, 논문에 있는 아래 그림을 보면 이해가 한층 편하다.

아래에 설명될 과정까지 포함해서 예를 들어 간단히 써보면 batch_size x channel x width x height 기준으로, 2 stage feautre의 shape이 1x50x 32x32 이고 3 stage는 1x100x16x16 이면 각 stage 단에서 feature patach의 개수 N만큼 모아 average pooling을 진행하고(shape은 같음), 2 stage 와 3 stage feature를 합치기 위해 interpolation을 진행하여 1x150x32x32 이런식으로 최종 feature는 생성된다. 이런식으로 모아진 32x32 feature들을 모두 모아놓고 coreset을 추출하는 방법이다.
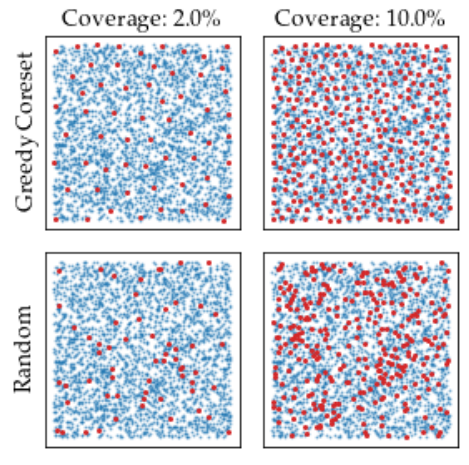
추론 과정에서 이미지가 정상인지 판별하기 위해서는 입력과 대조해보기 위한 비교군이 필요하다. 따라서, normal data에 대한 feature들을 memory bank에 저장해두고 활용한다. 단순하게 학습에 활용된 모든 이미지에 대한 feature들을 저장한다면 학습에 활용할 정상데이터가 많아질 수록 memory bank의 사이즈도 커진다. 결국 추론 시에 비교해야 하는 대상도 많아지기 때문에 memory bank의 사이즈는 추론 속도에 큰 영향을 미친다. 따라서, 메모리 뱅크의 효율적인 관리를 위해 Coreset-reduced patch-feature memory bank를 제안한다(일명 patchcore). 단순히 랜덤 샘플링으로 추출 할수도 있지만, 랜덤 샘플링의 경우 정상에 해당하는 feature들이 커버하는 영역에서 특정 영역에 밀집되어(확률적으로 많이 분포하는) 있을 수 있다. 추후 NN(nearest neighbor) 방법을 활용하여 detection을 하기 때문에 보다 균일하게 추출하기 위한 방법(minimax facility location coreset selection)을 활용하였다(해당 방법은 NP-Hard 한 문제여서 Greedy search를 통한 방법 활용). 방법론 자체로 보면 수학적으로 복잡하게 동작하지만, 개념적으로 보면 정상 이미지에 대한 feature들이 커버하는 영역을 최대한 균등하게 커버할 수 있는 coreset을 추출하는 것이다. normal data라면 memory bank를 생성할 때 가지고 있던 feautre 들과의 거리가 최대한 일정해야 NN으로 구분 했을 때 정상 비스무리한거는 놓치지 않으려면 당연한듯 하다. 논문에 있는 아래 그림을 참고하면 이해하기 좋다.
Coreset을 선정하는 과정에서 보다 빠른 추출을 위해 특징에 대해 차원 감소도 적용한다. 결과적으로 성능은 최대한 유지하면서도 보다 빠른 추론이 가능합니다.
최종적으로, 입력 이미지가 비정상인지를 판단하기 위한 점수(Image-level anomaly score)는 해당 이미지에 존재하는 모든 패치와 coreset 샘플 들과의 거리 중 가까운 것 중 가장 먼 값으로 설정된다. 비정상 요소를 segmentation 하기 위한 점수는(Patch-level anomaly score)는 대표 값을 따로 설정하지 않고 각 패치에 대한 특징의 점수를 개별로 계산하여, 위치에 맞게 원본 이미지 사이즈에 맞게 re-scaling을 진행한다.각 feature 들은 이미지의 특정 위치에 해당하는 정보를 포함하고 있기 때문에, 그림과 같이 에러 포인트를 localizaing 하는 효과도 기대할 수 있다.

Experiments
실험이야 뭐 늘 좋다는 내용이니, 훓어보는 수준에서 가볍게 보았다. 검출 성능에 대한 부분도 꽤나 인상적이지만 (AUROC 99/ 제일 낮은 것도 96.4) 보다 인상적인 내용은 활용 가능한 데이터가 적은(Low-shot) 환경에서의 실험에 대한 내용이다. 아래 표는 PatchCore를 추출하는데 활용된 이미지를 1장에서 50장 사이로 제한했을 때의 성능을 내고 있다. 실제로 실험을 해보았을 때도, 학습 이미지가 1/4 가량 줄어도 에러로 예측한 포인트들에는 큰 차이 없어 보이는 것을 확인 할 수 있었다.
Wrap-up
Anomaly detection는 학계에서 메인스트림은 아니지만 수요층이 확실히 있어서인지 지속적으로 연구가 이뤄지고 있는 것 같다(novelty detection, outlier, open-set 등 비슷한 카테고리의 연구들을 포함하면 어쩌면 매우 많이 연구 수요가 늘어나는 지도?) 발전하고 있는 것 같습니다. 비록, 제한적인 데이터 셋이지만(MVTec이 거의 유일...) 학습 데이터가 적은 와중에도 성능도 꾸준히 상승했다. 아마 실제 산업계에서 나온 데이터들에 대한 성능은 미지수이지만 목적과 환경에 따른 backbone 네트워크 다변화(고성능 모델, 경량 모델), backbone 네트워크에 추가적인 학습(transfer learning?) 등을 더하는 방식으로
다양한 환경에서 활용될 여지가 충분히 많은 것 같다. 관련해서 잘 정리된 코드도 있어 한번 돌려보기 좋아보인다. 개인적으로는 unofficial이 더 뜯어보긴 좋아보였다.
Official Code : GitHub - amazon-research/patchcore-inspection
Unofficial : GitHub - tiskw/patchcore-ad: Unofficial implementation of PatchCore and several additional experiments.







