
'책' 카테고리의 다른 글
| [23.03] 부의 인문학 (0) | 2023.03.06 |
|---|---|
| [23.03] 부자 아빠 가난한 아빠 (0) | 2023.03.06 |
| [23.02]레버리지 (0) | 2023.02.19 |
| [22.07] 7월 결산 (0) | 2022.08.01 |
| [22.04.28] 돈의 속성 - 김승호 (0) | 2022.04.30 |
| [23.03] 부의 인문학 (0) | 2023.03.06 |
|---|---|
| [23.03] 부자 아빠 가난한 아빠 (0) | 2023.03.06 |
| [23.02]레버리지 (0) | 2023.02.19 |
| [22.07] 7월 결산 (0) | 2022.08.01 |
| [22.04.28] 돈의 속성 - 김승호 (0) | 2022.04.30 |

| [23.03] 부의 레버리지 (0) | 2023.03.21 |
|---|---|
| [23.03] 부자 아빠 가난한 아빠 (0) | 2023.03.06 |
| [23.02]레버리지 (0) | 2023.02.19 |
| [22.07] 7월 결산 (0) | 2022.08.01 |
| [22.04.28] 돈의 속성 - 김승호 (0) | 2022.04.30 |

| [23.03] 부의 레버리지 (0) | 2023.03.21 |
|---|---|
| [23.03] 부의 인문학 (0) | 2023.03.06 |
| [23.02]레버리지 (0) | 2023.02.19 |
| [22.07] 7월 결산 (0) | 2022.08.01 |
| [22.04.28] 돈의 속성 - 김승호 (0) | 2022.04.30 |

오랜만에 한 권 완료
올해 목표 30권인데 1월은 날렸다.
이제라도 시작
| [23.03] 부의 레버리지 (0) | 2023.03.21 |
|---|---|
| [23.03] 부의 인문학 (0) | 2023.03.06 |
| [23.03] 부자 아빠 가난한 아빠 (0) | 2023.03.06 |
| [22.07] 7월 결산 (0) | 2022.08.01 |
| [22.04.28] 돈의 속성 - 김승호 (0) | 2022.04.30 |
올해 CVPR 2022 에서 발표된(arxiv 등을 통해 진작에 공개된) paperwithcode 기준으로 현재까지 state-of-the-art의 성능을 지닌 방법이라 읽어 봤다(더 자주 보고 정리해야하는데 큰일이다).
Anomaly detection 연구에 있어서 가장 어려운 점은 대부분의 abnormal data가 매우 드물다는 점이다. 그렇기 때문에, anomaly detection 관련 연구는 기본적으로 normal data의 본질적인 분포나 특징을 학습하는 것에 있습니다. 이를 위하여 autoencoder나 gan을 활용하여 네트워크 타겟 데이터에 대한 특징을 학습하도록 하는 연구도 많이 이루어졌었는데, 최근에는 이러한 과정 없이 ImageNet에 대해 pre-trained 네트워크에서 생성된 normal data 들의 feature의 분포를 바탕으로 학습하지 않은 abnormal(outlier)를 검출하는 방향으로 많은 연구가 진행되는 듯하다. 이런 접근 방식의 특징은 추가적인 학습을 필수로 진행하지 않는다는 점입니다. 하지만, 미리 pre-trained 된 네트워크는 학습된 데이터에 대해 어느정도 bias가 있을 수 밖에 없다. 이 논문에서는 그러한 문제점들을 해결하고 성능을 높이기 위한 방법을 제안한다.
normal한 data에 대한 feature를 추출하여 memory bank에 저장하는 과정은 필요하다. memory bank에 저장하는 건 anomaly detection 에선 이젠 매우 흔한 접근방법 인거 같다. 처음엔 feature space 자체를 제한하는 방식이 더 fancy하다고 생각했는데, 지금 생각해보면 memory bank를 활용하는게 성능측면에선 더 유리 한 듯 느껴진다.
PatchCore는 ImageNet에 대해 pre-trained된 backbone 네트워크를 활용한다(PaDiM, SPADE 등 비슷한 방법론 동일).방대한 데이터(ImageNet)에 대해서 학습된 네트워크는 비록 약간의 bias가 있을지라도(결국은 ImageNet 데이터의 class를 분류하는 것을 목적으로 학습되었기 때문에) 일반적인 이미지의 feature을 추출하기에 적합하다.딥러닝 기반의 특징을 활용하는 대다수의 방법들은 네트워크의 최종단에서 얻어진 특징을 활용한다. anomaly detection은 입력 이미지가 어떤 물체인지 분류하는 것이 목적은 아니지만 기 학습된(pre-trained) 네트워크를 통해 추출된 특징을 기준삼아 정상/비정상을 비교하는 것도 가능은 합니다.이 경우 이미지가 어떠한 특성을 가지는 지 분류하기 좋지만 지역적인 정보 측면에서는 손실이 있을 수 밖에 없다. 하지만, 주로 anomaly detection에서 관심있어 하는 부분은 주로 이미지의 굉장히 작은 부분에서 나타난다. 따라서, PatchCore에서는 Locally aware patch feature을 제안한다. 즉, 전체 네트워크의 마지막 단에서 추출된 특징을 활용하는 것이 아니라 중간에서 추출된 특징을 활용한다(Resnet50 기준 2,3 stage 마지막 단 feature). 네트워크의 중간에서 추출된 특징은 이미지의 일부분에 대한 특징이기 때문에 국소적인 차이를 구별하는데도 유용하다는게 저자의 주장이다. 하지만, 너무 작은 이미지 단위에 집중하면 정상 데이터안에서도 존재하는 작은 지역적 변화에 민감하게 반응 할 수 있기 때문에 PatchCore에서는 주변 특징들을 포함한 특징을 생성한다. 말로는 뭐 복잡해보이기는 한데, 논문에 있는 아래 그림을 보면 이해가 한층 편하다.

아래에 설명될 과정까지 포함해서 예를 들어 간단히 써보면 batch_size x channel x width x height 기준으로, 2 stage feautre의 shape이 1x50x 32x32 이고 3 stage는 1x100x16x16 이면 각 stage 단에서 feature patach의 개수 N만큼 모아 average pooling을 진행하고(shape은 같음), 2 stage 와 3 stage feature를 합치기 위해 interpolation을 진행하여 1x150x32x32 이런식으로 최종 feature는 생성된다. 이런식으로 모아진 32x32 feature들을 모두 모아놓고 coreset을 추출하는 방법이다.
추론 과정에서 이미지가 정상인지 판별하기 위해서는 입력과 대조해보기 위한 비교군이 필요하다. 따라서, normal data에 대한 feature들을 memory bank에 저장해두고 활용한다. 단순하게 학습에 활용된 모든 이미지에 대한 feature들을 저장한다면 학습에 활용할 정상데이터가 많아질 수록 memory bank의 사이즈도 커진다. 결국 추론 시에 비교해야 하는 대상도 많아지기 때문에 memory bank의 사이즈는 추론 속도에 큰 영향을 미친다. 따라서, 메모리 뱅크의 효율적인 관리를 위해 Coreset-reduced patch-feature memory bank를 제안한다(일명 patchcore). 단순히 랜덤 샘플링으로 추출 할수도 있지만, 랜덤 샘플링의 경우 정상에 해당하는 feature들이 커버하는 영역에서 특정 영역에 밀집되어(확률적으로 많이 분포하는) 있을 수 있다. 추후 NN(nearest neighbor) 방법을 활용하여 detection을 하기 때문에 보다 균일하게 추출하기 위한 방법(minimax facility location coreset selection)을 활용하였다(해당 방법은 NP-Hard 한 문제여서 Greedy search를 통한 방법 활용). 방법론 자체로 보면 수학적으로 복잡하게 동작하지만, 개념적으로 보면 정상 이미지에 대한 feature들이 커버하는 영역을 최대한 균등하게 커버할 수 있는 coreset을 추출하는 것이다. normal data라면 memory bank를 생성할 때 가지고 있던 feautre 들과의 거리가 최대한 일정해야 NN으로 구분 했을 때 정상 비스무리한거는 놓치지 않으려면 당연한듯 하다. 논문에 있는 아래 그림을 참고하면 이해하기 좋다.

Coreset을 선정하는 과정에서 보다 빠른 추출을 위해 특징에 대해 차원 감소도 적용한다. 결과적으로 성능은 최대한 유지하면서도 보다 빠른 추론이 가능합니다.
최종적으로, 입력 이미지가 비정상인지를 판단하기 위한 점수(Image-level anomaly score)는 해당 이미지에 존재하는 모든 패치와 coreset 샘플 들과의 거리 중 가까운 것 중 가장 먼 값으로 설정된다. 비정상 요소를 segmentation 하기 위한 점수는(Patch-level anomaly score)는 대표 값을 따로 설정하지 않고 각 패치에 대한 특징의 점수를 개별로 계산하여, 위치에 맞게 원본 이미지 사이즈에 맞게 re-scaling을 진행한다.각 feature 들은 이미지의 특정 위치에 해당하는 정보를 포함하고 있기 때문에, 그림과 같이 에러 포인트를 localizaing 하는 효과도 기대할 수 있다.

실험이야 뭐 늘 좋다는 내용이니, 훓어보는 수준에서 가볍게 보았다. 검출 성능에 대한 부분도 꽤나 인상적이지만 (AUROC 99/ 제일 낮은 것도 96.4) 보다 인상적인 내용은 활용 가능한 데이터가 적은(Low-shot) 환경에서의 실험에 대한 내용이다. 아래 표는 PatchCore를 추출하는데 활용된 이미지를 1장에서 50장 사이로 제한했을 때의 성능을 내고 있다. 실제로 실험을 해보았을 때도, 학습 이미지가 1/4 가량 줄어도 에러로 예측한 포인트들에는 큰 차이 없어 보이는 것을 확인 할 수 있었다.
Anomaly detection는 학계에서 메인스트림은 아니지만 수요층이 확실히 있어서인지 지속적으로 연구가 이뤄지고 있는 것 같다(novelty detection, outlier, open-set 등 비슷한 카테고리의 연구들을 포함하면 어쩌면 매우 많이 연구 수요가 늘어나는 지도?) 발전하고 있는 것 같습니다. 비록, 제한적인 데이터 셋이지만(MVTec이 거의 유일...) 학습 데이터가 적은 와중에도 성능도 꾸준히 상승했다. 아마 실제 산업계에서 나온 데이터들에 대한 성능은 미지수이지만 목적과 환경에 따른 backbone 네트워크 다변화(고성능 모델, 경량 모델), backbone 네트워크에 추가적인 학습(transfer learning?) 등을 더하는 방식으로
다양한 환경에서 활용될 여지가 충분히 많은 것 같다. 관련해서 잘 정리된 코드도 있어 한번 돌려보기 좋아보인다. 개인적으로는 unofficial이 더 뜯어보긴 좋아보였다.
Official Code : GitHub - amazon-research/patchcore-inspection
Unofficial : GitHub - tiskw/patchcore-ad: Unofficial implementation of PatchCore and several additional experiments.
Git에서는 이벤트가 생겼을 때, 스크립트를 실행 할 수 있도록 하는 hook이라는 기능이 있다.
coding convention 관련해서 필요하여 찾아서 정리하였다. 사실 내용 자체는 진즉에 쓰던 내용인데 늑장부리다가 이제서야 대충이라도 마무리에서 업로드한다..그마저도 사진 붙이기는 귀찮아서 미완성인채로...업로드(나중에 수정해야지)
무튼! Git에 있는 모든 repository에 이미 hook을 지원하고 있다(전혀 몰랐었음...).
현재 가지고 repository의 .git/hooks/ 경로에 진입하면 아래와 같은 파일들을 볼 수 있다.

.sample의 확장자를 가지고 있는 파일은 모두 git에서 제공하는 hook들 이다.
이 중에서, 코드 Lint/Formatting 목적으로 주로쓰이는 hook은 pre-commit 이다.
pre-commit은 commit 하기 전에 필수적으로 확인해야 할 것이 있을때 활용된다.
코드 스타일을 검사할 때 정말 많이 활용되는 것 같다. 구글에 검색해보면 예제도 엄청 많다.
직접 shell script을 작성해서 미리 설치된 formatter를 실행하도록 할수도 있지만,
파이썬은 쉽게 할 수 있는 플러그인이 있어서 편리하다.
가장 먼저 pre-commit 패키지를 설치한다.
$ pip install pre-commit
mac에서는 brew로 설치하면 되는 듯하다.
설치 후에 pre-commit-config.yaml 파일의 생성을 위해서 아래 명령어를 입력해준다.
$pre-commit sample-config >.pre-commit-config.yaml
나같은 경우 이렇게 하니 encoding type 관련된 에러가 발생하였는데, 그 때는 아래 명령어를 활용하면 된다.
$pre-commit sample-config | out-file .pre-commit-config.yaml -encoding utf8
그러면 sample conifg 파일이 생성된다.
config 파일에 사용할 플러그 인들에 대한 정보를 작성해 준다. 활용할 플러그인은 총 세개이다.
black : 코드 포멧팅 / flake8 : 코드 린트 / isort : 파이썬 import 정리
포멧팅을 하는데 굳이 린팅을 할 필요가 있나 싶긴한데, 찾아보니 py파일 말고 문서같은 것들을 위해 린트가 필요하다고 하긴하는데,
자바같은 경우 말고도 꼭 필요한진 잘모르겠다. 그리고, black의 경우 따로 configuration을 제공하진 않는데(yapf는 어느정도 제공해주긴함) 근데 formatting 자체가 일관된 코드 스타일을 맞추기 위해서 하는 것이고, python의 경우 PEP8이라는 확고한 스타일이 있다보니 딱히 필요없긴 한 것 같다. 어쨋든 각 플러그인의 설정을 위해 setup.cfg 파일도 작성해 준다.
마지막으로 아래 명령어를 작성하면 .git/hook 경로에 pre-commit 파일이 생기고,
다음에 commit 하면 자동으로 pre-commit이 진행된다!
$ pre-commit install
| [Git] hook을 활용한 통일성 있는 commit message (0) | 2022.08.01 |
|---|
ICML 2022 에서 발표된 논문들을 살펴보다가 또 그나마 익숙한 경량화 관련된 논문은 한편 정리하였다.
하지만, 이전 논문뿐만 아니라 기존 경량화 논문들이랑은 조금 다른 관점으로 연구가 진행되었고, 실용적인? 측면에서 의미가 있어보이는 논문이라 읽어 봤다.
딥러닝 모델의 성능이 향상될 수록 이를 활용하고자하는 어플리케이션의 범위도 넓어지고, 결국 실시간 추론이 가능한 모델에 대한 관심이 커지면서 효율적인 모델 설계 및 경량화에 대한 연구도 많이 진행되었다. 경량화에 대한 대부분의 연구들은 기본적으로 모델에서 이루어지는 연산량을 줄이는데 초점을 맞추고 있다(성능은 당연히 최대한 유지).
이 논문에서는 기존 연구들은 inference가 실제 H/W에서 구동됐을 때의 영향?을 고려하지 않았다고 얘기하고 있다.
MobileNet V2, EfficientNet과 같은 모델들은 상대적으로 가벼운 모델에 대한 요구로 탄생된 모델이다.
기존의 Conv layer 구조를 Depthwise, Pointwise Conv의 조합으로 분해하여 연산량(FLOPs)를 줄이면서도, 성능을 유지하였다. 하지만 실제로 하드웨어에서 구현해보면 기대만큼(연산량의 감소만큼) inference 속도가 빨라지지는 않는다.
이유인즉슨 inference 속도는 연산량(FLOPs)과 Memory Access Cost(MAC)의 영향을 받는다.
H/W에서 inference가 진행 될 때는 연산량 이외에도 MAC의 비중이 큰 데 기존의 연구들은 연산량 측면에서만 접근하고 있다(연산량자체가 이론적으로 다루기 좋은 주제라서 그런것 같기도?). 실제로 대부분의 논문들이 경량화의 근거로 제시하는게 연산량 및 # of parameter의 감소이다.
논문에서는 기존 연구 결과를 바탕으로 Conv layer를 Depthwise, Pointwise Conv들로 구성된 블럭으로 대체하는 것은 메모리 효율이나 속도가 떨어진다고 한다. 아래는 각 네트워크의 블락(Depthwise, Pointwise Convs)들을 같은 연산량을 가지는 Dense Conv. layer로 치환했을 때, fps를 나타낸 표이다.

H/W 측면에서는 같은 연산량을 가진 모델이면 layer의 개수가 적을 수록 메모리에 엑세스하는 횟수가 줄어서 더 효율이 좋다는 걸 알 수 있다. 실제로, 박사과정 중 수행했던 과제에서 Tensor Decomposition 활용해서 연산량을 매우 줄였는데 fps는 생각보다 큰 향상이 없었는데 이런 이유 때문이었던 거 같다.
정리하면 아래와 같다.
1) Shallow networks 가 H/W 효율이 좋다
: H/W에서 연산이 이루어지는 과정을 명확히는 알지는 못하지만 아마도 메모리에 데이터를 끌어온 뒤에 본격적인 계산이 이뤄지는 것 같다(당연한가?). MAC는 아마 데이터를 메모리 끌어오는 과정에서 소요되는 시간과 연관이 깊은 것 같다. GPU의 발전으로 한번에 계산할 수 있는 양은 증가하고 있지만, 한번에 끌어올 수 있는 메모리는 정해져 있나..? 이것도 증가한 거 아닌가(이 부분은 어렴풋한 느낌으로 무슨 말인지 알겠다 정도이지 완벽히 이해는 못한 것 같다. 컴퓨터 구조라도 열심히 들을걸). 쨋든, 요지는 적은 연산량이라도 layer의 개수가 느는 것 자체가 시간적인 측면에선 손해다! 인 듯
2) DNN의 linear operation은 합쳐질 수 있다
같은 연산량에서 layer가 적을수록 H/W 효율이 좋다면 이 논문에서 목표로 하는 실제 환경에서 빠른 inference가 가능하도록 하기 위해서는 layer의 숫자를 최대한으로 줄이는 게 좋다.
i딥러닝에서 이루어지는 연산은 대부분 linear operation 이다. linear의 linear는 또 다른 linear로 표현 가능하다. 만약 모델에서 이루어지는 모든 연산이 linear operation이면 layer 들을 integration 할 수 있다. 하지만 actiavation function을 통해 non-linear한 특성을 가지도록 해주고 있다. activation function만 제거할 수 있다 연속된 layer를 merge 할 수 있다.
문제는 activation의 역할이 굉장히 중요하다는 거?
3) avtivation function의 역할
activation function은 network가 non-linear한 특성을 가지도록하여 좋은 성능을 가지도록 한다. 기존의 경량화에 대한 연구(Ex. pruning)의 컨셉은 network에 존재하는 layer들은 학습이 더 잘되도록 돕지만, 결과적으로 불필요한 파라미터들도 포함하게 되기때문에, 결과에 영향 없이 특정 layer들을 제거할 수 있다는 것이다. activation function도 하나의 layer 중 하나로 non-linear 특성을 부과하여 학습을 도와주지만 모든 activation function이 추론 시에 필요하지 않다면 제거할 수 있다.
그래서, 불필요한 activation function을 찾아 제거하고 연속된 layer를 merge 할 수있다면 보다 높은 inference 속도를 얻을 수 있고 그 걸 해보겠다!는게 이 논문의 목적
1) 불필요한 activation function 찾기
당연하게도 적절하게 activation function의 중요성을 평가하는 것이 이 논문에서 가장 중요한 부분 중 하나이다.
중요성을 제대로 평가해야 성능 저하를 최소로 할 수 있기 때문에도 중요하다.
논문에서는 각 activation function의 중요도를 m 이란 파라미터로 측정한다. activation function의 중요도가 학습되게 하기 위하여 아래와 같은 수식을 설계하였다.

수식 자체는 그렇게 복잡하지 않다. m이 1에 가까울 수록, 원래의 activation function 그대로 적용되게 되고 0에 가까울수록 직전 layer의 아웃풋에 L번째 레이어에서 이루어지는 연산들(T)만 적용됩니다. activation function의 중요도는 미리 학습된 네트워크에 대해서 일정 에포크(epoch)를 돌려서 (논문의 경우 20) 측정합니다.
2) Fine-tuning
activation function의 중요도가 측정되면 중요도가 작은 순으로 k개의 레이어를 삭제한다. 이후 값을 보정해주기 위하여 fine-tuning을 진행한다. activation function 자체는 연산량적인 측면에서 보았을 때, inference 속도에 미치는 영향이 미미하지만 non-linear 한 특성을 부과하여 표현력?을 올려줘 성능 보전에 도움을 주므로 새로운 activation function을 추가한다. 추가적으로, Fine-tuning 과정에서 원본 모델을 활용하여 self-distillation을 진행하면 정확도를 더 끌어올리는 것도 가능하다.
3) 인접 레이어 병합
actiavation function이 제거된 후에는 모든 연산이 linear operation이기 때문에 새로운 수식으로 동일하게 표현 가능하다. 자세한 수식은 논문에 있으나, 어찌 보면 당연해서 생략하였다.
(Expand-the-Shrink) 논문에서는 이를 역으로 이용하여, 일반적인 컨볼루션을 Depthwise와 Pointwise conv 조합으로 쪼개고 학습 후 다시 합쳐서 학습 효율을 올릴 수도 있다고 얘기한다. 일종의 Idea 인 듯!
Tesla V100 / RTX 2080i / TX2 기반으로 실험을 진행하였다(ImageNet).
결과만 놓고 보면 정확도의 손실이 거의 없는 상태에서도 최소 1.5배 이상 inference 속도가 향상되었다..
약 2-3 퍼센트의 정확도 손실 범위 안에서 2.5배 까지도 inference 속도가 향상되었다. self-distillation을 활용하면 정확도 손실을 1퍼센트 안쪽으로 줄일 수 있다. 추가적으로, 논문에서 제안한 방법을 학습 기법으로 응용하여도 기존 네트워크 대비 약 1퍼센트 이상의 성능이 향상되었다. 기타 실험 결과들을 보면 초반 쪽에 존재하는 layer의 경우 input 사이즈가 커서 연산량은 많지만 결과에 미치는 영향이 상대적으로 적어서 주로 제일 먼저 삭제되는 것 같다. Tensor Decomposition 할 때도 그랬던 것 같기도...?
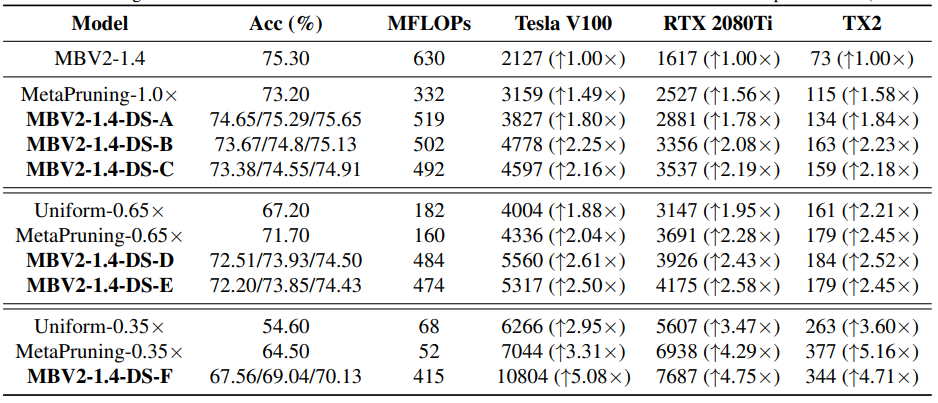
대부분의 경량화 논문은 성능을 유지하면서 연산량이나 파라미터 숫자를 줄이는 것을 목표로 하고 있다. 그와 달리 이번 논문은 성능 유지보다도 경량화를 통해 실제로 얻을 수 있는 inference 속도 향상에 초점이 잡혀있습니다. 실제로, 논문에 나타난 실험 구성들을 보더라도 inference 속도를 중요시 여기는 걸 알 수 있다. 실험 결과 inference 속도도 꽤나 향상된 걸 알 수 있다. 다만 MobileNet이나 EffiecientNet 같이 특정 Conv layer block 들(Depthwise + Pointwise)의 블록으로 구성된 모델에만 사용 가능한 것 같다?(Rep-VGG 논문을 열심히 들여다보진 않았지만 일반 Conv layer에 대한 문제들은 Rep-VGG에서 다뤄서 이 쪽으로 집중한 것 같기도 함). 해당 논문의 코드가 github에 공개되었기 때문에, 적용하여 성능과 inference 속도를 비교해 볼 수 있을 것 같다(https://github.com/facebookresearch/depthshrinkert). 꽤나 흥미로운 논문이었다.
| [이상탐지] Towards Total Recall in Industrial Anomaly Detection (0) | 2022.10.26 |
|---|---|
| [경량화] F8Net: Fixed-Point 8-bit Only Multiplication for Network Quantization (0) | 2022.08.20 |
경량화에 대한 논문 찾아보다가 ICLR 2022에서 구두 페이퍼로 발표되었길래 읽어보았다. open review 가서 리뷰 코멘트들을 읽어보면 모든 리뷰어가 좋게 평가한 것은 아니고 한 리뷰어가 슈퍼 극찬을 해서 구두로 올려준것 같다(이게 되네??).
사실 인트로의 경우는 특별한 내용이 있기 어려운 것같다, 대충 요약하면 이렇다.
대부분의 딥러닝 모델들은 실시간 추론이나 메모리 효율, 하드웨어 친숙성(부동소수점 연산이 불가한 환경) 등을 요구하는 분야에 적용되기에는 너무 무겁고 활용도가 제한적이다. 양자화 관련 연구들은 기존의 32bit 부동소수점으로 표현되는 모델들을 다양한 형태로 양자화함으로써 이러한 문제를 해결하고자 한다. 그러나 quantization error로 인한 성능의 저하는 피할 수 없기 때문에, 이를 해결하고자 한다. 강조하지만, 이 논문은 모든 연산이 8 bit 고정소수점으로 이루어진다. 심지어 더 정확하게.?!
컨트리뷰션은 세 가지인데, 결국은 8bit 고정소수점으로 양자화한다는 얘기고, 그걸위해서 뒷받침하는 논리나 적용하는 방법도 설명했다.
글의 구성은 전형적이면서도, 잘쓴거같다. 리뷰어들이 글은 잘썼다고 해서 얇은 귀가 동했는지도 모르겠다.
1) 여러 가지 실험을 통해 고정소수점만으로도 적은 오차로 기존의 부동소수점 형태의 숫자들을 양자화 할 수 있음을 증명.
2) 양자화 대상 값들의 통계적 특성에 따라서 최적의 고정소수점 포맷은 다르고 최적의 포맷은 간단히 구할 수 있음을 증명.
3) 고정소수점을 학습 과정에 적용하는 부분에 대한 기술적 방법 제안함. (기존 활성화 함수를 양자화하는 방법(PACT)과 결합, residual block과 같은 구조에도 학습할 수 있는 방법 등)
3,4 챕터는 각각 뒷받침 논리와 적용 방법으로 세부적인 내용은 다르긴 하지만 결국 컨트리뷰션에 언급한 내용이고, 쭈욱 따라가기에 흐름이 좋은거 같아서 그냥 한꺼번에 묶어서 정리했다.
1)고정소수점만으로도 적은 오차로 기존의 부동소수점 형태의 숫자들을 양자화 할 수 있다
시작 포인트는 8bit 고정소수점으로도 충분히 32비트 부동소수점 형식의 가중치들을 표현 가능한가? 이다. 얘기하고자하는 바가 8bit 고정소수점으로도 성능이 크게 떨어지지 않는 quantization가 가능하다는 것이라고 한다면, 어찌보면 가장 근원적인 질문이지 않을까?
weight 값들을 8bit 고정소수점으로 표현했을 때 얼마만큼 정확하게 기존의 값들을 표현할 수 있는 지 알아보기 위해서, 정규 분포(평균은 0으로 고정)를 가지는 값들을 여러가지 고정소수점 형식으로 변환했을 때 발생되는 상대 오차를 구한 그림이다. (Central-Limit Theorem에 의해서 weight들의 분포는 가우시안)
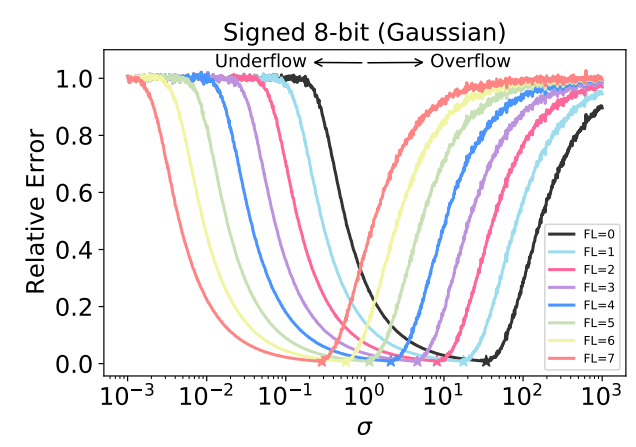
상대 오차가 1에 가까운 값이 되는 것은 해당 범위의 숫자를 제대로 표현할 수 없다는 것(Underflow/Overflow)이기에 제외한다고 해도 각 형식마다 다르긴하지만 어느 정도 범위안에서는 낮은 오차로 표현가능 한걸 알 수 있다.
정리하면 첫째, 다른 포맷을 가진 고정소숫점 숫자는 각기 다른 최적 표현 범위, 최소오차 최적의 표준편차를 가진다. 둘째, 큰 fractional length를 가질 수록 작은 숫자를 표현하는 데 유리하고 작은 fractional length를 가질수록 큰 숫자를 표현하는데 유리함을 증명함.
결과적으로, 각기 다른 분산을 가지고 있는 가중치 값들이라도 8-bit 고정소수점으로도 낮은 오차범위 안에서 충분히 표현 가능함.
2) 양자화 대상 값들의 통계적 특성에 따라서 최적의 고정소수점 포맷은 다르고 최적의 포맷은 간단히 구할 수 있다.
이 문제는 결국 두가지 질문으로 나눠 질수 있다. 첫째, 최적의 FL이 선택된다고 하면 어느 정도의 범위 안에 있는 숫자들이 낮은 오차를 가지고 양자화가 될 수 있는가? 만약 그렇다면 둘째, 최적의 FL 값이 손쉽게 구해질 수 있는가? 이 질문들에 대한 해답은 실험으로 해결했다.

그림에서 보면, Signed 8-bit 숫자의 경우 시그마 값이 0.1부터 100 에 조금 못 미치는 숫자까지는 굉장히 작은 에러를 통해 표현할 수 있는 것을 확인 할 수 있다(논문에는 unsigned의 경우에 대해서도 그림이 삽입되어 있음). 이러한 결과를 토대로 최적의 FL과 표준편차와의 관계를 모델링 하면 우측 그림과 같이 표현될 수 있다. 결과적으로, 고정소수점을 통해 양자화 하더라도 일정 범위 안에서는 굉장히 작은 오차를 가지고 변환가능하기 때문에 성능도 손실을 최소화하면서 양자화가 가능하고, 최적의 포맷도 간단히 구할 수 있다.
3) 고정소수점을 학습 과정에 적용하는 부분에 대한 기술적 방법
8 bit 고정소수점이 충분히 의미있는 표현이라고 한다면, 세번째 컨트리뷰션은 이를 어떻게 적용할 수 있는가에 대한 얘기이다. 대략 세 가지정도의 테크니컬한 이야기를 진행한다.
첫째는 Batch Normalization에 quantization 적용이다. Batch Normalization 과정에서 계속해서 업데이트 되는 값들(µ, σ)이 존재하는데, 이 것을 단순 quantization 을 적용하면 정확도 측면에서 손실이 있다(기존 연구에서 그런듯함). 우선 quantization 과정없이 feed-forward를 우선 진행하여 배치 정규화의 파라미터들을 모두 업데이트 해주고 난 뒤, 해당 파라미터들을 기반으로 quantization을 진행하고 다시 한번 feed-forwad 과정을 진행하고, back-propagation을 진행한다. (학습 후 정해진 고정소수점 포맷은 추론 과정에서는 변하지 않습니다)
둘째는 Activation function을 quantization 하는 방법에 대한 내용이다. weight 값은 quantization이 되더라도 학습 과정에서 quantization error가 보정이 될 여지가 있다. 그러나, activation function 에는 학습 가능한 파라미터가 없기 때문에, 학습을 통해 보상되는 과정이 없다. 게다가, 가장 많이쓰이는 활성화 함수인 ReLU는 결과값의 범위가 정해지지 않아서, quantization을 진행하기 어렵다. 이러한 문제를 극복하기 위해서 제안된게 PACT인데, PACT 논문에서는 ReLU 값의 범위를 제한하는 파라미터(α)를 도입하여, activation function quantization에 활용하였다. α가 학습 가능하도록 고안하여, α가 back propagation을 통해 적절하게 activation function의 결과값의 범위를 정할 수 있도록 해주어 quantization error가 감소하는 효과를 얻을 수 있다. 이 논문에서는 기존의 수식에 있는 scale factor 를 고정소수점 포맷에 관한 수식으로 정리하였다. 고정소수점 포맷도 두 번째 컨트리뷰션에 나와있듯 weight들의 분산으로 정해지기 때문에, 깔끔하게 구할수 있을듯 하다. 학습 과정에서 업데이트 되는 파라미터(α)가 존재하기때문에 batch normalization과 비슷하게 quantization을 진행한다.
셋째는 여러 개의 하위 레이어를 가지는 경우 quantization 적용이다. 각 레이어는 각 레이어에 최적화된 α값과 고정소수점 형식을 가지고 있다. 따라서, 연속된 레이어에서 앞선 레이어의 결과는 뒤따라오는 레이어의 고정소수점 형식으로 변환되어야 한다. 해당 연산이 부동 소수점 연산이기 때문에, 논문에서는 해당 과정을 앞선레이어 마지막 quantization 과정에 포함하여 이뤄 질 수 있도록 수식적으로 정리하였다. 이 때문에, 앞선 레이어의 결과를 계산하는데에 뒤따라오는 레이어에 관련된 파라미터들이 필요하게됨.

일반적으로 레이어가 하나하나씩 순차적으로 구성되어있으면 문제가 없겠지만, 그림과 같이 여러 개의 하위 레이어를 가지고 있는 경우에는 학습을 진행하면서 문제가 생길 수 있다. 자세히 기술되어 있지는 않지만, 학습 과정에서 일관성없는 값(각기 다른 하위 레이어 파라미터)들에 의해 상위 레이어의 학습이 잘 이루어지지 않는 문제가 있을 것 같다. 동일한 상위 레이어를 가지고 있는 경우에는 하나의 레이어를 마스터 레이어로 지정하여 해당 레이어의 파라미터를 동일한 레벨의 하위 레이어들이 공유함으로써 해결 했다. 그러나, 모든 파라미터를 공유할 경우 각 레이어의 값들을 표현하기에 적절한 비트 수가 차이가 날 때, 성능이 크게 하락한다고 한다. 아마, 다른 포맷으로 quantization이 진행되어서 underflow, overflow가 날 수 있을 거 같다. 결과적으론, α 값만 공유하도록 하였다. 실제로 α값을 제외하면 2의 자승 꼴을 가진 값들이기 때문에 약간의 비트 시프트 정도의 영향 밖에 없다고 하는데, 명확히 와닿지는 않는다.
그림은 미리 학습된 MobileNet V2의 각 레이어의 가중치 값의 분포와 , 제안하는 방법이 적용했을 때 선택된 FL을 나타낸다. weight 값들은 레이어마다 굉장히 다르지만 0.1 ~ 부터 4까지 다양한 값들을 가지고 있다. 논문에 제안된 방법을 적용할 경우 대부분 6,7,8,이긴 하지만 다양한 FL 표현이 될 수 있는 것을 볼 수 있다. 아마 리뷰 내용 중에 weight가 가지는 값의 범위가 거의 정해져있으니 대충 6,7,8로 선택지를 줄여서 하면 되지 않느냐는 기조의 질문도 있었던 거 같은데, 저자들이 실제로 해보니 그러면 성능 드랍이 꽤 컸다고 한다.

이외에, 다양한 네트워크 구조에 대하여 진행한 실험 결과를 보면, 성능이 거의 감소하지 않거나 오히려 오르기도 한다.(타겟 : 이미지넷 데이터 분류)결과적으로, 이 방법은 각 레이어와 activation function에 최적화된 quantization으로 오리지널 부동소수점 표현 값과 유사한 값으로 표현을 가능하게 해서 이러한 결과를 얻어낸 것 같다. 성능이 오른건 좀 신기하긴 하다.

논문 읽으며 좀 살펴보니 quantization awrae training 같은 경우에는 성능이 크게 저하되지 않는 수준까지 온 것 같다.
다소 아쉬운 점은, 아마도 저자가 강조하고 싶었던 부분이 '기존의 방법보다 정확한 표현을 통해 성능 저하를 막을 수 있다' 와 같은 기조이기 때문이겠지만, 추론 속도와 같은 실험 결과가 없는 것이다. 대부분의 리뷰어들도 이러한 부분을 지적했던거 같다. 코멘트에 대한 답변을 살펴보면, 단일 레이어에 대해서 실험했을 때 약 6~12(%) 정도의 향상이 있다고는 하지만 전체 레이어에 적용했을 때는 따로 언급이 없었다. 인트로에서는 부동소수점 연산이 불가능한 하드웨어에 대한 얘기를 두어번씩 하며 강조하더니, 그런 하드웨어에서 실험도 해주었으면 얼마나 좋았을까 싶다. 논문의 코드는 깃허브에 공개되었기 때문에, 적용하여 추론속도나 메모리에 대한 영향을 확인해 볼 수는 있을 것 같다.